│╠ą“åT▒žų¬8┤¾┼┼ą“3┤¾╦č╦„łD╬─įö╝ÜĮ╠│╠Ż©2Ż®
░l▒ĒĢrķgŻ║2023-07-28 üĒį┤Ż║├„▌xšŠš¹└ĒŽÓĻP▄ø╝■ŽÓĻP╬─š┬╚╦ÜŌŻ║
[š¬ę¬]│╠ą“åT▒žų¬8┤¾┼┼ą“3┤¾▓ķšęĮ╠│╠Ż©2Ż®╚²ĘN▓ķšę╦ŃĘ©:Ēśą“▓ķšęŻ¼Č■ĘųĘ©▓ķšęŻ©š█░ļ▓ķšęŻ®Ż¼ĘųēK▓ķšęŻ¼╔ó┴ą▒ĒŻ©ęį║¾šäŻ® ę╗ĪóĒśą“▓ķšęĄ─╗∙▒Š╦╝ŽļŻ║Å─▒ĒĄ─ę╗Č╦ķ_╩╝Ż¼Ēśą“Æ▀├Ķ▒ĒŻ¼ę└┤╬īóÆ▀├ĶĄĮĄ─ĮY³cĻPµIūų║═ĮoČ©...
│╠ą“åT▒žų¬8┤¾┼┼ą“3┤¾▓ķšęĮ╠│╠Ż©2Ż®
╚²ĘN▓ķšę╦ŃĘ©:Ēśą“▓ķšęŻ¼Č■ĘųĘ©▓ķšęŻ©š█░ļ▓ķšęŻ®Ż¼ĘųēK▓ķšęŻ¼╔ó┴ą▒ĒŻ©ęį║¾šäŻ®

ę╗ĪóĒśą“▓ķšęĄ─╗∙▒Š╦╝ŽļŻ║
Å─▒ĒĄ─ę╗Č╦ķ_╩╝Ż¼Ēśą“Æ▀├Ķ▒ĒŻ¼ę└┤╬īóÆ▀├ĶĄĮĄ─ĮY³cĻPµIūų║═ĮoČ©ųĄŻ©╝┘Č©×ķaŻ®ŽÓ▒╚▌^Ż¼╚¶«öŪ░ĮY³cĻPµIūų┼caŽÓĄ╚Ż¼ät▓ķšę│╔╣”Ż╗╚¶Æ▀├ĶĮY╩°║¾Ż¼╚į╬┤šęĄĮĻPµIūųĄ╚ė┌aĄ─ĮY³cŻ¼ät▓ķšę╩¦öĪĪŻ
šf░ū┴╦Š═╩ŪŻ¼Å─Ņ^ĄĮ╬▓Ż¼ę╗éĆę╗éĆĄž▒╚Ż¼šęų°ŽÓ═¼Ą─Š═│╔╣”Ż¼šę▓╗ĄĮŠ═╩¦öĪĪŻ║▄├„’@Ą─╚▒³cŠ═╩Ū▓ķšęą¦┬╩Ą═ĪŻ
▀mė├ė┌ŠĆąį▒ĒĄ─Ēśą“┤µā”ĮYśŗ║═µ£╩Į┤µā”ĮYśŗĪŻ

ėŗ╦ŃŲĮŠ∙▓ķšęķLČ╚ĪŻ
└²╚ń╔Ž▒ĒŻ¼▓ķšę1Ż¼ąĶę¬1┤╬Ż¼▓ķšę2ąĶę¬2┤╬Ż¼ę└┤╬═∙Ž┬═ŲŻ¼┐╔ų¬▓ķšę16ąĶę¬16┤╬Ż¼
┐╔ęį┐┤│÷Ż¼╬ęéāų╗ę¬īó▀@ą®▓ķšę┤╬öĄŪ¾║═Ż©╬ęéā│§ųąīWĄ─Ż¼╔ŽĄū╝ėŽ┬Ąū│╦ęįĖ▀│²ęį2Ż®Ż¼╚╗║¾│²ęįĮY³cöĄŻ¼╝┤×ķŲĮŠ∙▓ķšęķLČ╚ĪŻ
įOn=╣سcöĄ
ŲĮŠ∙▓ķšęķLČ╚=Ż©n+1Ż®/2
Č■ĪóČ■ĘųĘ©▓ķšęŻ©š█░ļ▓ķšęŻ®Ą─╗∙▒Š╦╝ŽļŻ║
Ū░╠߯║
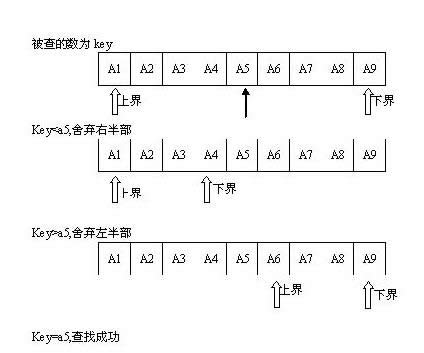
Ż©1Ż®┤_Č©įōģ^ķgĄ─ųą³c╬╗ų├Ż║mid=Ż©low+highŻ®/2
min┤·▒Ēģ^ķgųąķgĄ─ĮY³cĄ─╬╗ų├Ż¼low┤·▒Ēģ^ķgūŅū¾ĮY³c╬╗ų├Ż¼high┤·▒Ēģ^ķgūŅėęĮY³c╬╗ų├
Ż©2Ż®īó┤²▓ķaųĄ┼cĮY³cmidĄ─ĻPµIūųŻ©Ž┬├µė├R[mid].keyŻ®▒╚▌^Ż¼╚¶ŽÓĄ╚Ż¼ät▓ķšę│╔╣”Ż¼Ę±ät┤_Č©ą┬Ą─▓ķšęģ^ķgŻ║
╚ń╣¹R[mid].key>aŻ¼ätė╔▒ĒĄ─ėąą“ąį┐╔ų¬Ż¼R[mid].keyėęé╚Ą─ųĄČ╝┤¾ė┌aŻ¼╦∙ęįĄ╚ė┌aĄ─ĻPµIūų╚ń╣¹┤µį┌Ż¼▒ž╚╗į┌R[mid].keyū¾▀ģĄ─▒ĒųąĪŻ▀@Ģrhigh=mid-1
╚ń╣¹R[mid].key<>< span="">ätĄ╚ė┌aĄ─ĻPµIūų╚ń╣¹┤µį┌Ż¼▒ž╚╗į┌R[mid].keyėę▀ģĄ─▒ĒųąĪŻ▀@Ģrlow=mid<>
╚ń╣¹R[mid].key=aŻ¼ät▓ķšę│╔╣”ĪŻ
Ż©3Ż®Ž┬ę╗┤╬▓ķšęßśī”ą┬Ą─▓ķšęģ^ķgŻ¼ųžÅ═▓Į¾EŻ©1Ż®║═Ż©2Ż®
Ż©4Ż®į┌▓ķšę▀^│╠ųąŻ¼lowų▓Įį÷╝ėŻ¼highų▓Į£p╔┘Ż¼╚ń╣¹high<>< span="">Ż¼ät▓ķšę╩¦öĪĪŻ<>
ŲĮŠ∙▓ķšęķLČ╚=Log2(n+1)-1
ūóŻ║ļm╚╗Č■ĘųĘ©▓ķšęĄ─ą¦┬╩Ė▀Ż¼Ą½╩Ūę¬īó▒Ē░┤ĻPµIūų┼┼ą“ĪŻČ°┼┼ą“▒Š╔Ē╩Ūę╗ĘN║▄┘MĢrĄ─▀\╦ŃŻ¼╦∙ęįČ■ĘųĘ©▒╚▌^▀mė├ė┌Ēśą“┤µā”ĮYśŗĪŻ×ķ▒Ż│ų▒ĒĄ─ėąą“ąįŻ¼į┌Ēśą“ĮYśŗųą▓Õ╚ļ║═äh│²Č╝▒žĒÜęŲäė┤¾┴┐Ą─ĮY³cĪŻę“┤╦Ż¼Č■Ęų▓ķšę╠žäe▀mė├ė┌─ŪĘNę╗ĮøĮ©┴óŠ═║▄╔┘Ė─äėČ°ėųĮø│ŻąĶę¬▓ķšęĄ─ŠĆąį▒ĒĪŻ
╚²ĪóĘųēK▓ķšęĄ─╗∙▒Š╦╝ŽļŻ║
Č■Ęų▓ķšę▒Ē╩╣ĘųēKėąą“Ą─ŠĆąį▒Ē║═╦„ę²▒ĒŻ©│ķ╚ĪĖ„ēKųąĄ─ūŅ┤¾ĻPµIūų╝░ŲõŲ╩╝╬╗ų├śŗ│╔╦„ę²▒Ē
Ż®ĮM│╔Ż¼ė╔ė┌▒Ē╩ŪĘųēKėąą“Ą─Ż¼╦∙ęį╦„ę²▒Ē╩Ūę╗éĆ▀fį÷ėąą“▒ĒŻ¼ę“┤╦▓╔ė├Ēśą“╗“Č■Ęų▓ķšę╦„ę²▒ĒŻ¼ęį┤_Č©┤²▓ķĮY³cį┌──ę╗ēKŻ¼ė╔ė┌ēKā╚¤oą“Ż¼ų╗─▄ė├Ēśą“▓ķšęĪŻ
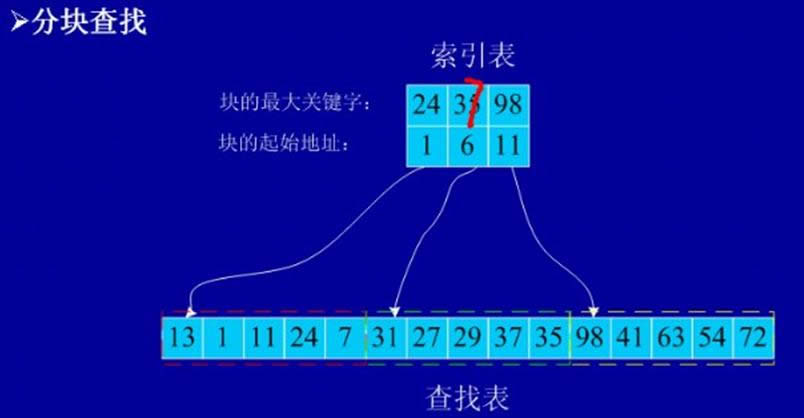
įO▒Ē╣▓néĆĮY³cŻ¼ĘųbēKŻ¼s=n/b
(ĘųēK▓ķšę╦„ę²▒Ē)ŲĮŠ∙▓ķšęķLČ╚=Log2Ż©n/s+1Ż®+s/2
(Ēśą“▓ķšę╦„ę²▒Ē)ŲĮŠ∙▓ķšęķLČ╚=(S2+2S+n)/(2S)
ūóŻ║ĘųēK▓ķšęĄ─ā׳c╩Ūį┌▒Ēųą▓Õ╚ļ╗“äh│²ę╗éĆėøõøĢrŻ¼ų╗꬚ęĄĮįōėøõø╦∙ī┘ēKŻ¼Š═į┌įōēKųą▀Mąą▓Õ╚ļ╗“äh│²▀\╦ŃŻ©ę“ēKā╚¤oą“Ż¼╦∙ęį▓╗ąĶę¬┤¾┴┐ęŲäėėøõøŻ®ĪŻ╦³ų„ę¬┤·ār╩Ūį÷╝ėę╗éĆ▌oų·öĄĮMĄ─┤µā”┐ž╝■║═īó│§╩╝▒ĒĘųēK┼┼ą“Ą─▀\╦ŃĪŻ
╦³Ą─ąį─▄Įķė┌Ēśą“▓ķšę║═Č■Ęų▓ķšęų«ķgĪŻ
╦─Īóį┌└ĒŽļŪķørŽ┬Ż¼¤oĒÜ╚╬║╬▒╚▌^Š═┐╔ęįšęĄĮ┤²▓ķĻPµIūųŻ¼▓ķšęĄ─Ų┌═¹Ģrķg×ķO(1)ĪŻ╔ó┴ą▒Ē▓ķšę╝╝ąg▓╗═¼ė┌Ēśą“▓ķšęĪóČ■Ęų▓ķšęĪóĘųēK▓ķšęĪŻ╦³▓╗ęįĻPµIūųĄ─▒╚▌^×ķ╗∙▒Š▓┘ū„Ż¼▓╔ė├ų▒ĮėīżųĘ╝╝ągĪŻ
ŽŻ═¹╬ęĄ─▀@éĆ┤¾╝ęėą╦∙Ä═ų·Ż¼ėøĄ├į┌▀@Ų¬╚šųŠŽ┬├µ╗“š▀ų„ĒōĄ─┴¶čį░Õųą┴¶Ž┬─ŃéāĄ─Į©ūh║═Ę┤üŻ¼▀@ą®ī”╬ęéā╩ŪūŅīÜ┘FĄ─žöĖ╗Ż¼ŅAūŻ┤¾╝ę┐ņśĘŻĪėąå¢Ņ}┤¾╝ęĘeśO╗ž╠¹ėæšōŽ┬╣■ŻĪ
īW┴ĢĮ╠│╠┐ņ╦┘šŲ╬šÅ─╚ļķTĄĮŠ½═©Ą─ļŖ─Xų¬ūR
