MySQLųą▒ĒĘųģ^(q©▒)Ą─įö╝ÜĮķĮB
░l(f©Ī)▒ĒĢrķgŻ║2023-07-20 üĒį┤Ż║├„▌xšŠš¹└ĒŽÓĻP(gu©Īn)▄ø╝■ŽÓĻP(gu©Īn)╬─š┬╚╦ÜŌŻ║
[š¬ę¬]MySQL▒ĒĘųģ^(q©▒)║═ĘųÄņĘų▒Ēę╗śėŻ¼Č╝╩Ū×ķ┴╦╠ßĖ▀öĄ(sh©┤)ō■(j©┤)ÄņĄ─═╠═┬┴┐ĪŻĘųģ^(q©▒)ŅÉ╦Ų┼cĘų▒ĒŻ¼Ęų▒Ē╩Ū▀ē▌ŗ╔Žīóę╗éĆ┤¾öĄ(sh©┤)ō■(j©┤)┴┐Ą─▒ĒĘų│╔ČÓéĆŻ¼┐╔ęį╩Ū╦«ŲĮĘųę▓┐╔ęį╩Ū┤╣ų▒ĘųĪŻČ°Ęųģ^(q©▒)╩Ūīó▒ĒĄ─ę╗éĆöĄ(sh©┤)ō■(j©┤)╬─╝■▓Ęų│╔ČÓéĆĪŻ▓╗═¼Ą─öĄ(sh©┤)ō■(j©┤)▓ĘųĄĮ...
MySQL▒ĒĘųģ^(q©▒)║═ĘųÄņĘų▒Ēę╗śėŻ¼Č╝╩Ū×ķ┴╦╠ßĖ▀öĄ(sh©┤)ō■(j©┤)ÄņĄ─═╠═┬┴┐ĪŻĘųģ^(q©▒)ŅÉ╦Ų┼cĘų▒ĒŻ¼Ęų▒Ē╩Ū▀ē▌ŗ╔Žīóę╗éĆ┤¾öĄ(sh©┤)ō■(j©┤)┴┐Ą─▒ĒĘų│╔ČÓéĆŻ¼┐╔ęį╩Ū╦«ŲĮĘųę▓┐╔ęį╩Ū┤╣ų▒ĘųĪŻČ°Ęųģ^(q©▒)╩Ūīó▒ĒĄ─ę╗éĆöĄ(sh©┤)ō■(j©┤)╬─╝■▓Ęų│╔ČÓéĆĪŻ▓╗═¼Ą─öĄ(sh©┤)ō■(j©┤)▓ĘųĄĮ▓╗═¼Ą─╬─╝■ųąĪŻ▀@śėī”ė┌ę╗éĆöĄ(sh©┤)ō■(j©┤)┴┐ĘŪ│Ż┤¾Ą─▒ĒŻ¼ėąČÓéĆöĄ(sh©┤)ō■(j©┤)╬─╝■üĒ▀Mąą┤µā”Ż¼▀@śėŠ═╠ßĖ▀┴╦öĄ(sh©┤)ō■(j©┤)ÄņĄ─ io ąį─▄ĪŻ╝╚╚╗╩Ūßśī”Ą─öĄ(sh©┤)ō■(j©┤)▒ĒĄ─╬─╝■▀Mąą▓┘ū„Ż¼─Ū├┤╬ęéāŠ═ąĶꬎ╚üĒ┴╦ĮŌ MySQL ▒ĒĄ─┤µā”ĪŻ╬ęéāų¬Ą└Ż¼MySQL ėąČÓĘN┤µā”ę²ŪµŻ¼▓╗═¼Ą─┤µā”ę²Ūµ╦∙┤µā”Ą─╬─╝■Ė±╩Į▓╗═¼ĪŻ▀@└’ų„ę¬ęį InnoDB ║═ MyISAM ▀@ā╔ĘN┤µā”ę²ŪµüĒšf├„ĪŻ
InnoDB
.frm ╬─╝■ öĄ(sh©┤)ō■(j©┤)▒ĒĄ─ĮY(ji©”)śŗ(g©░u)
.idb ╬─╝■ ▒ĒĄ─öĄ(sh©┤)ō■(j©┤)╬─╝■Ż¼¬ÜŽĒ▒Ē┐šķgŻ¼├┐éĆ▒Ēėąę╗éĆ.idb ╬─╝■
.ibdata ╬─╝■ ▒ĒĄ─öĄ(sh©┤)ō■(j©┤)╬─╝■Ż¼╣▓ŽĒ▒Ē┐šķgŻ¼╦∙ėąĄ─▒Ē╩╣ė├▀@ę╗éĆöĄ(sh©┤)ō■(j©┤)
╬─╝■
MyISAM
.frm ╬─╝■ öĄ(sh©┤)ō■(j©┤)▒ĒĄ─ĮY(ji©”)śŗ(g©░u)
.myd ╬─╝■ öĄ(sh©┤)ō■(j©┤)╬─╝■
.myi ╬─╝■ ╦„ę²╬─╝■
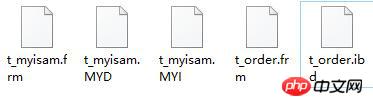
╩ūŽ╚ę¬▓ķ┐┤ę╗Ž┬╬ęéā«ö(d©Īng)Ū░Ą─öĄ(sh©┤)ō■(j©┤)Äņ░µ▒Š╩Ūʱų¦│ųĘųģ^(q©▒)
1 show variables like '%partition%';
╚ń║╬▀MąąĘųģ^(q©▒)─žŻ┐į┌▀MąąöĄ(sh©┤)ō■(j©┤)Äņ╦«ŲĮŪąĘųĄ─Ģr║“╬ęéāų¬Ą└Ż¼╦«ŲĮŪąĘų┐╔ęįĖ∙ō■(j©┤)ųĖČ©ūųČ╬╚Ī─ŻĄ─ĘĮ╩ĮüĒĘųĄĮ▓╗═¼Ą─▒ĒųąŻ¼ę▓┐╔ęįĖ∙ō■(j©┤)╚šŲ┌üĒ▀MąąŪąĘųŻ¼╗“š▀Ė∙ō■(j©┤) id üĒĘųČ╬Ż¼1-100 ╚fį┌Ą┌ę╗Åł▒ĒųąŻ¼100 ╚f┴Ń 1 ĄĮ 200 ╚fį┌Ą┌Č■Åł▒Ēųąęį┤╦ŅÉ═ŲĄ╚Ą╚ĪŻ┐éų«╬ęéāį┌▀MąąŪąĘųĄ─▀^│╠ųąėą║▄ČÓĄ─═ŠÅĮĪŻ─Ū├┤į┌▒ĒĘųģ^(q©▒)╔ŽöĄ(sh©┤)ō■(j©┤)Äņę▓Įo╬ęéā╠ß╣®┴╦ČÓĘNĘĮ░Ė┐╔╣®╬ęéā▀xō±ĪŻ
MySQL ▒ĒĘųģ^(q©▒)▓▀┬į
RANGE Ęųģ^(q©▒) ╗∙ė┌ī┘ė┌ę╗éĆĮoČ©▀B└m(x©┤)ģ^(q©▒)ķgĄ─┴ąųĄŻ¼░čČÓąąĘų┼õĮoĘųģ^(q©▒)
1 DROP TABLE IF EXISTS `p_range`;
2 CREATE TABLE `p_range` (
3 `id` int(10) NOT NULL AUTO_INCREMENT,
4 `name` char(20) NOT NULL,
5 PRIMARY KEY (`id`)
6 ) ENGINE=MyISAM AUTO_INCREMENT=9 DEFAULT CHARSET=utf8
7 /*!50100 PARTITION BY RANGE (id)
8 (PARTITION p0 VALUES LESS THAN (8) ENGINE = MyISAM) */;
ūŅ┤¾ųĄ
1 PARTITION BY RANGE (id)
2 (
3 PARTITION p0 VALUES LESS THAN (8),
4 PARTITION p1 VALUES LESS THAN MAXVALUE)
▀mė├ł÷Š░Ż║
▀@śėŠ═▒Ē╩ŠŻ¼╦∙ėą id ┤¾ė┌ 7 Ą─öĄ(sh©┤)ō■(j©┤)ėøõø┤µį┌į┌ p1 Ęųģ^(q©▒)└’ĪŻ
RANGE Ęųģ^(q©▒)į┌╚ńŽ┬ł÷║Ž╠žäeėąė├Ż║
Īż«ö(d©Īng)ąĶę¬äh│²Ī░┼fĄ─Ī▒öĄ(sh©┤)ō■(j©┤)ĢrĪŻ╚ń╣¹─Ń╩╣ė├╔Ž├µūŅĮ³Ą──ŪéĆ└²ūėĮo│÷Ą─Ęųģ^(q©▒)ĘĮ░ĖŻ¼─Ńų╗ąĶ║åå╬Ąž╩╣ė├ Ī░ALTER TABLE employees DROP PARTITION p0Ż╗Ī▒üĒäh│²╦∙ėąį┌ 1991 ─ĻŪ░Š═ęčĮø(j©®ng)═Żų╣╣żū„Ą─╣═åTŽÓī”æ¬(y©®ng)Ą─╦∙ėąąąĪŻī”ė┌ėą┤¾┴┐ąąĄ─▒ĒŻ¼▀@▒╚▀\ąąę╗éĆ╚ńĪ░DELETE FROM employees WHERE YEAR(separated) <=
1990Ż╗Ī▒▀@śėĄ─ę╗éĆ DELETE ▓ķįāę¬ėąą¦Ą├ČÓĪŻ
ĪżŽļę¬╩╣ė├ę╗éĆ░³║¼ėą╚šŲ┌╗“ĢrķgųĄŻ¼╗“░³║¼ėąÅ─ę╗ą®Ųõ╦¹╝ēöĄ(sh©┤)ķ_╩╝į÷ķLĄ─ųĄĄ─┴ąĪŻ
ĪżĮø(j©®ng)│Ż▀\ąąų▒Įėę└┘ćė┌ė├ė┌ĘųĖŅ▒ĒĄ─┴ąĄ─▓ķįāĪŻ└²╚ńŻ¼«ö(d©Īng)ł╠(zh©¬)ąąę╗éĆ╚ń
Ī░SELECT COUNT(*) FROM employees WHERE YEAR(separated) = 2000 GROUP BY store_idŻ╗Ī▒
▀@śėĄ─▓ķįāĢrŻ¼MySQL ┐╔ęį║▄čĖ╦┘Ąž┤_Č©ų╗ėąĘųģ^(q©▒) p2 ąĶę¬Æ▀├ĶŻ¼▀@╩Ūę“×ķėÓŽ┬Ą─Ęųģ^(q©▒)▓╗┐╔─▄░³║¼ėąĘ¹║Žįō WHERE ūėŠõĄ─╚╬║╬ėøõø
LIST Ęųģ^(q©▒) ŅÉ╦Ųė┌░┤ RANGE Ęųģ^(q©▒)Ż¼ģ^(q©▒)äeį┌ė┌ LIST Ęųģ^(q©▒)╩Ū╗∙ė┌┴ąųĄŲź┼õę╗éĆļx╔óųĄ╝»║ŽųąĄ──│éĆųĄüĒ▀Mąą▀xō±ĪŻ
1 DROP TABLE IF EXISTS `p_list`;
2 CREATE TABLE `p_list` (
3 `id` int(10) NOT NULL AUTO_INCREMENT,
4 `typeid` mediumint(10) NOT NULL DEFAULT '0',
5 `typename` char(20) DEFAULT NULL,
6 PRIMARY KEY (`id`,`typeid`)
7 ) ENGINE=MyISAM AUTO_INCREMENT=9 DEFAULT CHARSET=utf8
8 /*!50100 PARTITION BY LIST (typeid)
9 (PARTITION p0 VALUES IN (1,2,3,4) ENGINE = MyISAM, PARTITION p1 VALUES IN (5,6,7,8) ENGINE = MyISAM) */;
HASH Ęųģ^(q©▒) ╗∙ė┌ė├æ¶Č©┴xĄ─▒Ē▀_╩ĮĄ─ĘĄ╗žųĄüĒ▀Mąą▀xō±Ą─Ęųģ^(q©▒)Ż¼įō▒Ē▀_╩Į╩╣ė├īóę¬▓Õ╚ļĄĮ▒ĒųąĄ─▀@ą®ąąĄ─┴ąųĄ▀Mąąėŗ╦ŃĪŻ▀@éĆ║»öĄ(sh©┤)┐╔ęį░³║¼ MySQL ųąėąą¦Ą─Īó«a(ch©Żn)╔·ĘŪžōš¹öĄ(sh©┤)ųĄĄ─╚╬║╬▒Ē▀_╩ĮĪŻ HASH Ęųģ^(q©▒)ų„ę¬ė├üĒ┤_▒ŻöĄ(sh©┤)ō■(j©┤)į┌ŅA(y©┤)Ž╚┤_Č©öĄ(sh©┤)─┐Ą─Ęųģ^(q©▒)ųąŲĮŠ∙Ęų▓╝ĪŻį┌ RANGE ║═ LIST Ęųģ^(q©▒)ųąŻ¼▒žĒÜ├„┤_ųĖČ©ę╗éĆĮoČ©Ą─┴ąųĄ╗“┴ąųĄ╝»║Žæ¬(y©®ng)įō▒Ż┤µį┌──éĆĘųģ^(q©▒)ųąŻ╗Č°į┌ HASH Ęųģ^(q©▒)ųąŻ¼MySQL ūįäė═Ļ│╔▀@ą®╣żū„Ż¼─Ń╦∙ę¬ū÷Ą─ų╗╩Ū╗∙ė┌īóę¬▒╗╣■ŽŻĄ─┴ąųĄųĖČ©ę╗éĆ┴ąųĄ╗“▒Ē▀_╩ĮŻ¼ęį╝░ųĖČ©▒╗Ęųģ^(q©▒)Ą─▒Ēīóę¬▒╗ĘųĖŅ│╔Ą─Ęųģ^(q©▒)öĄ(sh©┤)┴┐
1 DROP TABLE IF EXISTS `p_hash`;
2 CREATE TABLE `p_hash` (
3 `id` int(10) NOT NULL AUTO_INCREMENT,
4 `storeid` mediumint(10) NOT NULL DEFAULT '0',
5 `storename` char(255) DEFAULT NULL,
6 PRIMARY KEY (`id`,`storeid`)
7 ) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8
8 /*!50100 PARTITION BY HASH (storeid)9 PARTITIONS 4 */;
║åå╬³cšfŠ═╩ŪöĄ(sh©┤)ō■(j©┤)Ą─┤µ╚ļ┐╔ęį░┤ partition by hash(expr); ▀@└’Ą─ expr ┐╔ęį
╩ŪµI├¹ę▓┐╔ęį╩Ū▒Ē▀_╩Į▒╚╚ń YEAR(time)Ż¼╚ń╣¹╩Ū▒Ē▀_╩ĮĄ─ŪķørŽ┬
Ī░Ą½╩Ūæ¬(y©®ng)«ö(d©Īng)ėøūĪŻ¼├┐«ö(d©Īng)▓Õ╚ļ╗“Ė³ą┬Ż©╗“š▀┐╔─▄äh│²Ż®ę╗ąąŻ¼▀@éĆ▒Ē▀_╩ĮČ╝ę¬ėŗ
╦Ńę╗┤╬Ż╗▀@ęŌ╬Čų°ĘŪ│ŻÅ═(f©┤)ļsĄ─▒Ē▀_╩Į┐╔─▄Ģ■ę²Ųąį─▄å¢Ņ}Ż¼ė╚Ųõ╩Ūį┌ł╠(zh©¬)ąą═¼Ģr
ė░Ēæ┤¾┴┐ąąĄ─▀\╦ŃŻ©└²╚ń┼·┴┐▓Õ╚ļŻ®Ą─Ģr║“ĪŻ Ī▒
į┌ł╠(zh©¬)ąąäh│²Īóīæ╚ļĪóĖ³ą┬Ģr▀@éĆ▒Ē▀_╩ĮČ╝Ģ■ėŗ╦Ńę╗┤╬ĪŻ
öĄ(sh©┤)ō■(j©┤)Ą─Ęų▓╝▓╔ė├╗∙ė┌ė├æ¶║»öĄ(sh©┤)ĮY(ji©”)╣¹Ą──ŻöĄ(sh©┤)üĒ┤_Č©╩╣ė├──éĆŠÄ╠¢Ą─Ęųģ^(q©▒)ĪŻōQŠõįÆŻ¼ī”ė┌ę╗éĆ▒Ē▀_╩ĮĪ░exprĪ▒Ż¼īóę¬▒Ż┤µėøõøĄ─Ęųģ^(q©▒)ŠÄ╠¢×ķ N Ż¼ŲõųąĪ░N = MOD(expr, num)Ī▒ĪŻ
▒╚╚ń╔Ž├µĄ─ storeid ×ķ 10Ż╗─Ū├┤ N=MOD(10,4) ;N ╩ŪĄ╚ė┌ 2 Ą─Ż¼─Ū├┤▀@ŚlėøõøŠ═┤µā”į┌ p2 Ą─Ęųģ^(q©▒)└’├µĪŻ
╚ń╣¹▓Õ╚ļę╗éĆ▒Ē▀_╩Į┴ąųĄ×ķ'2005-09-15ĪõĄ─ėøõøĄĮ▒ĒųąŻ¼─Ū├┤▒Ż┤µįōŚlėøõøĄ─Ęųģ^(q©▒)┤_Č©╚ńŽ┬Ż║MOD(YEAR('2005-09-01Īõ),4) = MOD(2005,4) = 1 ; Š═┤µā”į┌ p1 Ęųģ^(q©▒)└’├µ┴╦ĪŻ
Ęųģ^(q©▒)ūóęŌ³c
1Īóųžą┬Ęųģ^(q©▒)ĢrŻ¼╚ń╣¹įŁĘųģ^(q©▒)└’├µ┤µį┌ maxvalue ätą┬Ą─Ęųģ^(q©▒)└’├µę▓▒žĒÜ░³║¼
maxvalue ʱätŠ═Õeš`ĪŻ
alter table p_range2x
reorganize partition p1,p2
into (partition p0 values less than (5), partition p1 values less than maxvalue);
[Err] 1520 ©C Reorganize of range partitions cannot change total ranges except for last partition where it can extend the range
2ĪóĘųģ^(q©▒)äh│²ĢrŻ¼öĄ(sh©┤)ō■(j©┤)ę▓═¼śėĢ■▒╗äh│² alter table p_range drop partition p0;
3Īó╚ń╣¹ range Ęųģ^(q©▒)┴ą▒Ē└’├µø]ėą maxvalue ät╚ńėąą┬öĄ(sh©┤)ō■(j©┤)┤¾ė┌¼F(xi©żn)į┌Ęųģ^(q©▒) range öĄ(sh©┤)ō■(j©┤)ųĄ─Ū├┤▀@éĆöĄ(sh©┤)ō■(j©┤)╩Ū¤oĘ©īæ╚ļĄĮöĄ(sh©┤)ō■(j©┤)Äņ▒ĒĄ─ĪŻ
4Īóą▐Ė─▒Ē├¹▓╗ąĶę¬ äh│²Ęųģ^(q©▒)║¾į┌▀MąąĖ³Ė─Ż¼ą▐Ė─▒Ē├¹║¾Ęųģ^(q©▒)┤µā” myd myi ī”æ¬(y©®ng)ę▓Ģ■ūįäėĖ³Ė─ĪŻ
╚ń╣¹ŽŻ═¹Å─╦∙ėąĘųģ^(q©▒)äh│²╦∙ėąĄ─öĄ(sh©┤)ō■(j©┤)Ż¼Ą½╩Ūėų▒Ż┴¶▒ĒĄ─Č©┴x║═▒ĒĄ─Ęųģ^(q©▒)─Ż╩ĮŻ¼╩╣ė├ TRUNCATE TABLE ├³┴ŅĪŻŻ©šłģóęŖ 13.2.9 ╣Ø(ji©”)Ż¼Ī░TRUNCATE šZĘ©Ī▒Ż®ĪŻ
╚ń╣¹ŽŻ═¹Ė─ūā▒ĒĄ─Ęųģ^(q©▒)Č°ėų▓╗üG╩¦öĄ(sh©┤)ō■(j©┤)Ż¼╩╣ė├Ī░ALTER TABLE ĪŁ REORGANIZE PARTITIONĪ▒šZŠõĪŻģóęŖŽ┬├µĄ─ā╚(n©©i)╚▌Ż¼╗“š▀į┌ 13.1.2 ╣Ø(ji©”)Ż¼Ī░ALTER TABLE šZĘ©Ī▒ ųąģó┐╝ĻP(gu©Īn)ė┌ REORGANIZE PARTITION Ą─ą┼ŽóĪŻ
5Īóī”▒Ē▀MąąĘųģ^(q©▒)ĢrŻ¼▓╗šō▓╔ė├──ĘNĘųģ^(q©▒)ĘĮ╩Į╚ń╣¹▒Ēųą┤µį┌ų„µI─Ū├┤ų„µI▒žĒÜį┌Ęųģ^(q©▒)┴ąųąĪŻ▒ĒĘųģ^(q©▒)Ą─ŠųŽ▐ąįĪŻ
6Īólist ĘĮ╩ĮĘųģ^(q©▒)ø]ėąŅÉ╦Ųė┌ range ─ŪĘN less than maxvalue Ą─īæĘ©Ż¼ę▓Š═╩Ūšf list Ęųģ^(q©▒)▒ĒĄ─╦∙ėąöĄ(sh©┤)ō■(j©┤)Č╝▒žĒÜį┌Ęųģ^(q©▒)ūųČ╬Ą─ųĄ┴ą▒Ē╝»║ŽųąĪŻ
7Īóį┌ MySQL 5.1 ░µųąŻ¼═¼ę╗éĆĘųģ^(q©▒)▒ĒĄ─╦∙ėąĘųģ^(q©▒)▒žĒÜ╩╣ė├═¼ę╗éĆ┤µā”ę²ŪµŻ╗└²╚ńŻ¼▓╗─▄ī”ę╗éĆĘųģ^(q©▒)╩╣ė├ MyISAMŻ¼Č°ī”┴Ēę╗éĆ╩╣ė├ InnoDBĪŻ
8ĪóĘųģ^(q©▒)Ą─├¹ūų╩Ū▓╗ģ^(q©▒)Ęų┤¾ąĪīæĄ─Ż¼myp1 ┼c MYp1 ╩ŪŽÓ═¼Ą─ĪŻ
ęį╔ŽŠ═╩ŪMySQLųą▒ĒĘųģ^(q©▒)Ą─įö╝ÜĮķĮBĄ─įö╝Üā╚(n©©i)╚▌Ż¼Ė³ČÓšłĻP(gu©Īn)ūóphpųą╬─ŠW(w©Żng)Ųõ╦³ŽÓĻP(gu©Īn)╬─š┬ŻĪ
īW(xu©”)┴Ģ(x©¬)Į╠│╠┐ņ╦┘šŲ╬šÅ─╚ļķTĄĮŠ½═©Ą─SQLų¬ūRĪŻ
